でっちあげ 〜福岡「モンスター教師」事件:正義、メディア、そして争われた真実を巡る10年間〜
序章:メディア・ストームの解剖
本件の公的な物語は、一つの地方記事から始まり、全国的なスキャンダルへと燃え広がった。この過程は、事件そのものの事実関係と同じくらい、その後の展開を決定づける上で重要な役割を果たした。世論がどのように形成され、一人の教師が「モンスター」へと仕立て上げられていったのかを理解することは、この複雑な事件の全貌を解明するための第一歩である。
発火点:地方ニュースとしての第一報
事件が最初に公になったのは、2003年6月27日の朝日新聞(西部本社版)の記事であった 1。この記事は「小4の母『曾祖父は米国人』 教諭、直後からいじめ」という見出しを掲げ、物語の基本的な枠組みを提示した。すなわち、アメリカ人の血を引く児童、その出自を理由に人種差別的ないじめを行う教師、そして息子を守ろうとする母親という構図である。この時点では、事件はまだ福岡都市圏のローカルニュースに過ぎなかったが、後の爆発的な報道合戦の土台となる核心的な要素――人種、体罰、教師という権威――は、この時点で既に設定されていた 1。
全国的な炎上:「殺人教師」の誕生
事件が一気に全国区の注目を集めるきっかけとなったのは、同年10月9日号の『週刊文春』の記事であった 1。この記事は「『死に方教えたろうか』と教え子を恫喝した史上最悪の『殺人教師』」という衝撃的な見出しと共に、教師の実名と顔写真を掲載した 1。この報道は、テレビのワイドショーがこぞって後追いする引き金となり、連日のようにセンセーショナルな報道が繰り返される事態を招いた 1。
この報道の特異性は、単に疑惑を報じるのではなく、断罪を先行させた点にある。誰も死んでいないにもかかわらず「殺人教師」というレッテルを貼ることは、極めて強い予断を読者に与えるものであった 3。この強力な物語の枠組みは、疑惑の段階で一人の教師を社会的に抹殺するに等しい効果を持った。報道はもはや単なる情報の伝達者ではなく、学校、教育委員会、そして教師本人に絶大な圧力をかける、事件の主要な当事者そのものへと変貌したのである。このようにして形成された「極悪非道な教師と可哀想な被害者」という単純明快な二項対立の構図は、その後の司法判断や行政処分にも見えない影響を及ぼし続けることとなる。
事件概要:疑惑、被告、そして原告
本件の中心には、衝撃的な一連の疑惑と、それを取り巻く主要な関係者が存在する。公式記録では匿名化されているため、本報告では報道や関連書籍で用いられている仮名を適宜使用し、事件の具体的な内容と当事者を明らかにする。
関係者のプロフィール
- 教師: 裁判記録では「B」と表記されている 4。ノンフィクション書籍『でっちあげ』で用いられた仮名に基づき、本報告では**川上譲(かわかみ ゆずる)**と呼称する 1。事件当時46歳で、当該小学校に赴任して1年目の教師であった 5。
- 児童とその家族: 裁判記録では原告として、児童がX1、父親がX2、母親がX3とされている 4。同じく『でっちあげ』に基づき、児童を
浅川裕二(あさかわ ゆうじ)(当時小学4年生、9歳)、母親を**浅川和子(あさかわ かずこ)**と呼称する 1。 - 学校: 福岡市が設置した公立小学校。具体的な校名は公表されていないが、所在地は福岡市西区であることが判明している 5。
- 被告: 民事訴訟における主たる被告は、教師の使用者であり学校の設置者である福岡市であった 2。
疑惑のカタログ
浅川家によって主張され、メディアによって増幅された疑惑は、以下の通り多岐にわたり、その内容は極めて深刻であった 1。
- 家庭訪問と「穢れた血」発言: 2003年5月12日の家庭訪問の際、川上教諭が裕二少年の赤みがかった髪の色に気づき、母親の和子から裕二の曾祖父がアメリカ人であることを聞き出すと、「穢れた血(けがれたち)」という言葉を使い、人種差別的な発言を長時間にわたって繰り返したとされる 1。
- 「10カウント」と「5つの刑」: 授業後の帰りの会で、裕二少年に対し、10秒という不可能な時間内に片付けを強要。失敗すると、「アンパンマン」(両頬を強くつねる)、「ミッキーマウス」(両耳を強く引っ張る)、「ピノキオ」(鼻血が出るほど鼻を捻る)、「アイアンクロー」(顔面を鷲掴みにして突き飛ばす)、「グリグリ」(こめかみを拳で押さえつける)という、漫画に由来する名前が付けられた5種類の「刑」から一つを選ばせて実行したとされる 1。
- 教室での屈辱: 授業中、川上教諭は裕二少年に対し、アメリカ人の血が混じっていることを理由に「頭が悪い」と繰り返し罵倒し、クラスのゲームでは「髪が赤いけん、お前が鬼になれ」と言って、意図的に鬼の役に仕向けたとされる 1。
- 身体的虐待と傷害: 上記の「刑」により、裕二少年は大量の鼻血、ちぎれて化膿した耳、折れた歯、太ももの打撲など、日常的に怪我が絶えなかったと主張された 1。
- 自殺教唆: 最も深刻な疑惑として、川上教諭が裕二少年に対し、「穢れた血の人間は生きている価値がない。早く死ね、自分で死ね」と述べ、自殺を強要したとされる。これにより少年は自宅マンションからの投身自殺を図ったとまで主張された 1。
- PTSD(心的外傷後ストレス障害)の診断: これら一連の虐待行為が原因で、裕二少年は重度のPTSDを発症し、大学病院の精神科閉鎖病棟への長期入院を余儀なくされたとされた 1。
これらの疑惑は、その一つ一つが教師としてあるまじき行為であり、組み合わさることで「史上最悪の殺人教師」というメディアが作り上げたイメージを強力に補強するものであった。
表1:福岡「教師によるいじめ」事件の時系列(2003年~2013年)
本事件は、最初の告発から最終的な行政裁決まで10年という長い歳月を要した。民事訴訟と行政不服審査という二つの異なる手続きが並行して進んだため、その全体像を把握するには時系列での整理が不可欠である。以下の表は、事件の主要な出来事を年代順にまとめたものである 5。
| 日付 | 出来事 |
|---|---|
| 2003年 | |
| 4月 | 川上教諭(46歳)、福岡市西区の市立小学校4年3組の担任となる。 |
| 5月12日 | 川上教諭が浅川家を家庭訪問。 |
| 5月30日 | 浅川夫妻が学校に対し、家庭訪問時の差別発言や体罰について最初の抗議を行う。 |
| 6月17日 | 川上教諭が浅川夫妻に対し、「いじめていました」と謝罪。 |
| 6月23日 | 学校側が保護者懇談会で経緯を説明し、川上教諭の担任交代を発表。 |
| 6月27日 | 朝日新聞(西部本社)が本事件を初めて報道。 |
| 8月22日 | 福岡市教育委員会が、川上教諭に対し停職6か月の懲戒処分を決定。 |
| 10月2日 | 『週刊文春』が「殺人教師」の見出しで実名報道。同日、主治医が裕二少年をPTSDと診断。 |
| 10月8日 | 浅川家が福岡市と川上教諭を相手取り、福岡地裁に損害賠償請求訴訟を提起(当初約1300万円)。 |
| 10月10日 | 川上教諭が福岡市人事委員会に対し、懲戒処分の取り消しを求めて審査請求を行う。 |
| 10月14日 | 裕二少年が久留米大学病院精神神経科の閉鎖病棟に入院(~2004年4月16日)。 |
| 2004年 | |
| 2月2日 | 第2回口頭弁論にて、川上教諭側が体罰や差別発言の事実を全面的に否認し、争う姿勢を示す。 |
| 2006年 | |
| 7月28日 | 第一審判決(福岡地裁)。被告福岡市に対し220万円の支払いを命じる。川上教諭個人への請求は棄却。 |
| 8月10日 | 浅川家側が福岡高裁に控訴。福岡市も附帯控訴。 |
| 2007年 | |
| 3月5日 | 浅川家側が、川上教諭個人に対する控訴を取り下げ。これにより教諭への請求棄却が確定。 |
| 7月9日 | 裕二少年の本人尋問が非公開で実施される。 |
| 2008年 | |
| 11月25日 | 控訴審判決(福岡高裁)。被告福岡市の賠償額を330万円に増額。双方が上告せず判決確定。 |
| 判決確定後 | |
| 川上教諭が申し立てていた人事委員会での懲戒処分に関する審理が再開される。 | |
| 2013年 | |
| 1月17日 | 福岡市人事委員会が裁決。川上教諭に対する停職6か月の懲戒処分をすべて取り消す。 |
第I部:法廷闘争 - 二つの裁判所の物語
民事訴訟の経過は、単なる事実認定の過程ではなかった。それは、法的手続きと訴訟戦略が複雑に絡み合い、必ずしも客観的な真実とは一致しない「法的な現実」を形成していくプロセスであった。
第1章:地方裁判所の判決(2006年)
第一審である福岡地方裁判所の判決は、一見すると原告側の部分的な勝利であったが、その内実には後の展開を予見させる重要な判断が含まれていた。
判決内容
2006年7月28日、福岡地裁(野尻純夫裁判長)は、被告である福岡市に対し、裕二少年へ220万円の損害賠償を支払うよう命じた。しかし、同時に、原告らが求めていた川上教諭個人に対する損害賠償請求は棄却した 5。
事実認定と判断の射程
裁判所は、川上教諭の行為の一部(ランドセルをゴミ箱に置いた行為や一部の発言など)を不法行為と認定し、使用者である福岡市の責任を認めた。この点が、メディアで「市の敗訴」と報じられた根拠である。しかし、判決の核心はむしろ、棄却された部分にある。原告側が約5800万円まで膨らませた請求額に対し、認定された賠償額が220万円と低額であったこと、そして何よりも、一連の行為の張本人とされた川上教諭個人への請求が退けられたことは、裁判所が原告の主張するような深刻かつ悪質な虐待行為や、それによって引き起こされたとされる重度のPTSDという物語の全体像を、そのままの形では認定しなかったことを示唆している 2。
PTSDを巡る攻防
裁判では、裕二少年のPTSD診断が大きな争点となった。原告側は主治医である前田正治医師の診断書を提出し、深刻な精神的被害を訴えた。一方、被告側は東邦大学の黒木宣夫助教授による医学的意見書を提出。この意見書は、前田医師の診断過程における事実確認の不十分さや、母親の供述に過度に依存している可能性を指摘し、PTSDは誤診の可能性が高いと結論付けていた 5。この「専門家対専門家」の対立の中で、裁判所は原告の主張するPTSDの存在とその原因について、全面的には追認しなかった。
この第一審判決が示したのは、明確な白黒ではない、ある種の曖昧さであった。市の賠償責任が認められたことで、原告側は「勝訴」を主張できた。しかし、教諭個人への請求棄却は、メディアが作り上げた「史上最悪の殺人教師」という人格像を司法が認定しなかったことを意味する。この判決は、どちらの当事者にとっても完全な勝利でも敗北でもなく、控訴審という次の舞台へ続く、いわば序章に過ぎなかったのである。
第2章:戦略的撤退 - 高等裁判所の控訴審(2008年)
控訴審では、原告側弁護団による一つの訴訟戦略が、裁判の枠組みそのものを変え、第一審とは異なる結論を導き出す決定的な要因となった。この展開は、法廷における「真実」が、時に手続きによっていかに左右されるかを如実に示している。
法廷戦術の妙
控訴審において、原告側は驚くべき手を打った。それは、川上教諭個人に対する控訴を取り下げるという決定であった 5。原告側は、その理由を「児童本人が、教諭が訴訟に関与しないのであれば本人尋問に応じたいと決意したから」と説明した 5。しかし、この戦術的撤退は、裁判の力学を根本から変える極めて重大な法的帰結をもたらした。
法的手続きがもたらした結果
この控訴取り下げにより、川上教諭は被告の立場から、福岡市を補助する「補助参加人」という立場に変わった 2。民事訴訟法上、補助参加人は、自らが補助する当事者(この場合は福岡市)が法廷で認めた(あるいは積極的に争わなかった)事実について、それに反する主張をすることができない。
福岡市は、事件発覚当初から教諭への聞き取り調査を行い、懲戒処分を下し、保護者に対して謝罪を行っていた。この過程で、市は教諭による一定の「不適切な指導」があったことを事実上認めていた。第一審では、教諭自身が被告としてこれらの事実を争うことができた。しかし控訴審では、補助参加人となった教諭が市の「自白」を覆す主張をしても、裁判所はそれを法的に考慮する義務を失ったのである。控訴審判決文には「川上は、被告ではなく被控訴人(福岡市)の補助参加人なので、被控訴人が自白している事実を争うことはできない」と明確に記されている 2。
高等裁判所の判決
2008年11月25日、福岡高等裁判所(石井宏治裁判長)は、福岡市に対し、賠償額を330万円に増額する判決を言い渡した 2。判決は、第一審と同様の事実関係を認定しつつ、「裕二は川上の不法行為により、通院治療をせざるを得なかったと認められる」との一文を加え、治療との因果関係をより明確に認めた上で賠償額を引き上げた 2。
この判決は、新たな証拠によって教諭の行為の悪質性がより強く証明された結果ではない。むしろ、原告側の訴訟戦略によって、教諭が事実関係を争う法的手段を封じられた結果、福岡市が既に認めていた事実が「争いのない事実」として確定し、それに基づいて賠償額が算定された、という手続き上の帰結であった。事実認定そのものは第一審から変わっていないにもかかわらず、賠償額が増額されたという一見矛盾した結果は、この法的手続きの「罠」によって生み出されたのである。これは、司法の判断が、客観的な事実の探求だけでなく、当事者の訴訟戦略や法的手続きの制約によって大きく左右されるという現実を浮き彫りにした。
第II部:逆調査 - 「でっちあげ」の物語
民事訴訟が進行する一方で、ジャーナリストによる独自の調査と、行政機関による懲戒処分の妥当性審査という、二つの異なる流れが「教師によるいじめ」という当初の物語に根本的な疑問を投げかけていた。
第3章:ジャーナリストの探求と書籍『でっちあげ』
ジャーナリスト福田ますみによる徹底した取材は、書籍『でっちあげ―福岡「殺人教師」事件の真相―』として結実し、メディアが報じた物語とは全く異なるもう一つの「真実」を提示した 2。
疑惑の解体
福田ますみの調査によって明らかにされたとされる事実は、原告側の主張の根幹を揺るがすものであった。
- 「アメリカ人の血」という虚構: 裁判の過程で、浅川家にはアメリカ人の血が一滴も流れていないことが判明したとされている。これが事実であれば、事件の出発点とされた人種差別という動機そのものが崩壊する 2。
- 矛盾する証言: 非公開で行われた裕二少年の本人尋問では、証言に多くの矛盾が露呈したとされる。特に、母親が主張した事件の引き金である「家庭訪問で『穢れた血』という言葉を聞いた」という点について、少年自身が「聞こえなかった」と証言したことは決定的であった 2。
- 「幸せな」日記: 原告側が裕二少年の精神的苦痛の証拠として提出したとされる英語の日記は、その全文が開示されると、「僕は元気です。幸せです」「学校を楽しんでいます」といった、主張とは真逆の内容が記されていたという 2。
- 疑わしいPTSD診断: 書籍では、PTSD診断の際に母親の和子が同席し、質問に対して積極的に発言するなど、診断が母親の供述に強く誘導されたものである可能性が指摘されている。これは、第一審で被告側が提出した専門家の意見書の内容とも合致する 2。
- 裏付け証拠の欠如: あれほど凄惨なものとして語られた「10カウント」や日常的な身体的虐待について、他の児童や保護者からの客観的な目撃証言は一切得られなかった。また、大量の鼻血や折れた歯といった傷害を裏付ける当時の診断書なども提出されなかった 2。
これらの調査結果は、当初の報道がいかに一方的な情報に基づいていたかを示唆し、事件が母親の虚言とメディアの妄信によって作り上げられた「でっちあげ」であるという、衝撃的な仮説を提示した。
第4章:雪冤 - 人事委員会の最終裁決(2013年)
民事訴訟が確定した後、川上教諭が停職処分を不服として申し立てていた行政審査が最終局面を迎えた。この福岡市人事委員会による裁決は、事件の公的な結論を180度覆すものであった。
異なる審理の場
福岡市人事委員会は、損害賠償を争う民事裁判所とは目的も権限も異なる行政機関である。その唯一の目的は、福岡市教育委員会が下した停職6か月という懲戒処分が、事実に基づいており、かつ公正であったかを審査することであった 5。人事委員会は、民事訴訟における当事者の「自白」や訴訟戦略に縛られることなく、独自の事実調査と証拠評価を行う権限を持っていた。
全面的な処分の取り消し
2013年1月17日、人事委員会は驚くべき裁決を下した。それは、川上教諭に対する停職6か月の懲戒処分を、理由がないとしてすべて取り消すというものであった 5。これは、教諭の完全な雪冤を意味した。
体系的な疑惑の否定
裁決は、処分理由とされた個々の疑惑を体系的に検討し、そのほとんどを「認められない」または「虚偽である」と結論付けた 5。
- 家庭訪問時の差別発言や学校での体罰、それによる怪我については、ことごとく「認められない」と判断。
- 児童の持ち物をごみ箱に入れた行為は、いじめではなく「教育指導目的」と認定しつつも、指導としては「行き過ぎ」であったと付言した。
- 自殺教唆やPTSDについては、そもそも懲戒処分の理由に含まれていなかったため「審査せず」とした。
さらに裁決は、事件がこじれた原因の一端が学校管理職の対応にあったと指摘。校長や教頭が事実関係を十分に調査しないまま、川上教諭に謝罪を強要したことが、事態を悪化させたと断じた 5。
この裁決は、10年近くにわたって「いじめ教師」の烙印を押され続けた一人の教師の名誉を、行政手続きの最終段階で回復させるものとなった。
表2:判断の比較分析:民事裁判所 vs. 人事委員会
本事件の最も不可解な点は、同じ事実関係を対象としながら、民事裁判所と行政機関である人事委員会が全く異なる結論に至ったことである。この相違を明確にするため、主要な争点に対する各機関の判断を以下の表で比較する 5。
| 争点(原告側の主張) | 民事裁判所の判断(高裁判決) | 福岡市人事委員会の裁決 |
|---|---|---|
| 家庭訪問での差別発言 (「穢れた血」など) | 市が自白したため争点とならず、不法行為の背景事情として考慮。 | 「児童らの主張は虚偽というべきである」として否定。 |
| 学校での体罰 (「10カウント」など) | 市が自白したため争点とならず、不法行為として認定。 | 「認められない」として否定。 |
| 体罰による怪我 | 不法行為と傷害の因果関係を一部認定(治療費を賠償額に算入)。 | 「認められない」として否定。 |
| 授業中の差別発言 | 市が自白したため争点とならず、不法行為として認定。 | 「認められない」として否定。 |
| ランドセルをゴミ箱に捨てた行為 | 不法行為として認定。 | 「教育指導目的」と認定。ただし「指導としても行き過ぎ」と付言。 |
| 自殺教唆発言 | 判決では明確に言及せず。 | 審査対象外(懲戒処分の理由に含まれないため)。 |
| PTSD発症 | 不法行為との因果関係を認定し、賠償額を増額。 | 審査対象外(懲戒処分の理由に含まれないため)。 |
| 総合的な結論 | 福岡市の損害賠償責任を認定(330万円)。 | 懲戒処分をすべて取り消し。いじめの事実は認められない。 |
この表が示すのは、二つの機関における「真実」の決定的な断絶である。民事裁判所、特に控訴審は、被告である福岡市の「自白」と原告側の訴訟戦略という手続き的な制約の中で、事実上、原告側の主張の一部を認定せざるを得なかった。一方で、そのような制約から自由な立場で、証拠に基づいた純粋な事実認定を行った人事委員会は、疑惑のほとんどを退けた。この対立構造こそが、本事件の謎を解く鍵となる。
第III部:分析と結論
10年にわたる複雑な経過を経て、本事件は二つの相容れない「公的な結論」を残した。一つは、市の賠償責任を認めた民事訴訟の確定判決。もう一つは、教師の懲戒処分を完全に取り消した行政裁決である。この矛盾を解き明かし、事件が残した教訓を考察することが、本報告の最終的な目的である。
第5章:判決の矛盾を読み解く - 法律、手続き、そして真実
なぜ、同じ事案に対して司法と行政は正反対の結論に至ったのか。その答えは、それぞれの機関が持つ目的と、課せられた手続きの根本的な違いにある。
異なる責務、異なる目標
民事訴訟の目的は、当事者間の紛争を法に基づいて解決することにある。裁判所は、提出された証拠に基づき、「証拠の優越(preponderance of the evidence)」の原則、すなわち、どちらの主張がより確からしいかに基づいて事実を認定する。そして、当事者が法廷で認めた事実(自白)は、原則としてそのまま判決の基礎となる。
一方、人事委員会のような行政不服審査機関の目的は、行政処分(この場合は懲戒処分)が、事実に基づき、法に則って適正に行われたかを審査することにある。ここでは、処分を下した行政庁(市教育委員会)が、処分の根拠となる事実を立証する責任を負う。民事訴訟のような当事者間の戦略に左右されず、職権で証拠を調査し、より実体的な真実の探求を目指す。
手続きという罠、再び
この事件における決定的な分岐点は、控訴審で原告側が教師個人への控訴を取り下げたことであった。この一手により、教師は事実関係を直接争う当事者の地位を失い、福岡市の「自白」という手続き的な壁に阻まれた 2。高裁判決は、この手続き上の制約の中で下された、いわば「法的な擬制」の上になりたつ判断であった。それは、客観的な真実の探求というよりも、既存の枠組みの中で法的な紛争を終結させるための結論であった。
決定的な要因:事実認定か、紛争解決か
最終的に、この事件の矛盾は、「純粋な事実認定」と「法的な紛争解決」という二つの異なるプロセスの衝突として説明できる。人事委員会は、メディアの喧騒や訴訟戦略から切り離された場で、証拠を一つ一つ吟味し、実体的な事実認定を行った唯一の機関であった。その結果が、疑惑の全面的な否定と処分の取り消しであった。対照的に、民事裁判所は、当事者の主張と手続きに縛られた中で、法的な紛争を解決するという役割を遂行した。その結果が、市の賠償責任を認めるという、もう一つの「真実」であった。この二つの結論は矛盾しているように見えるが、それぞれの制度的な役割と制約を理解すれば、なぜこのような乖離が生じたのかを論理的に説明することが可能となる。
結論:現代の魔女狩りが残した永続的な傷跡
福岡「教師によるいじめ」事件は、一人の教師の名誉が回復されるという形で一応の終結を見た。しかし、その10年という歳月が残した傷跡は深く、現代社会における正義と真実の脆弱性について、重い教訓を突きつけている。
メディアによる裁判
本件は、裏付けの取れていない一方的な主張に基づき、メディアがいかにして一個人の評判を破壊しうるかを示す、冷徹なケーススタディである。「殺人教師」という烙印は、一度押されてしまえば、たとえ法的に潔白が証明された後でも、完全に消し去ることは不可能に近い 1。センセーショナルな物語への渇望が、公平な報道というジャーナリズムの基本原則をいかに容易に侵食するかを、この事件は白日の下に晒した。
組織の責任
原告側の主張が最終的に虚偽であったと認定されたとしても、事件の初期段階における学校管理職と市教育委員会の対応に重大な問題があったことは見過ごせない。彼らが、公平かつ徹底した事実調査を怠り、クレーマーとも言える保護者の要求に安易に屈して謝罪を強要したことが、事態を収拾不可能なまでにこじらせ、メディアが介入する隙を与えた 2。組織的なリスク管理の失敗が、一人の教員をスケープゴートにする結果を招いたのである。
正義まで10年
最終的な結論として、この事件が示す最も sobering な現実は、一人の人間が自らの潔白を証明するために要した、計り知れないほどの個人的、職業的コストである。2013年に雪冤を果たすまで、川上教諭は10年もの間、法廷闘争、社会的な非難、そして停職という苦難に耐えなければならなかった 3。この事件は、説得力のある物語と組織の弱さを前にしたとき、真実がいかに脆いものであるか、そして、一度失われた信頼と名誉を回復する道がいかに長く険しいものであるかを、痛烈に物語っている。「モンスター」のレッテルを貼られてから名誉を回復するまでの旅路は、私たちの社会が持つ公的、そして法的な正義のメカニズムに、深刻な欠陥が存在することを示唆してやまないのである。
")
引用文献
- 試し読み | 『でっちあげ―福岡「殺人教師」事件の真相―』福田ますみ | 新潮社, 6月 28, 2025にアクセス、 https://www.shinchosha.co.jp/book/131181/preview/
- 『でっちあげ―福岡「殺人教師」事件の真相―』 福田ますみ - 新潮社, 6月 28, 2025にアクセス、 https://www.shinchosha.co.jp/book/131181/
- 『でっちあげ―福岡「殺人教師」事件の真相』驚愕の結末 - HONZ, 6月 28, 2025にアクセス、 https://honz.jp/articles/-/42439
- 福岡高等裁判所判決平成18年 (ネ) 第720号, 6月 28, 2025にアクセス、 https://ja.wikisource.org/wiki/%E7%A6%8F%E5%B2%A1%E9%AB%98%E7%AD%89%E8%A3%81%E5%88%A4%E6%89%80%E5%88%A4%E6%B1%BA%E5%B9%B3%E6%88%9018%E5%B9%B4_(%E3%83%8D)_%E7%AC%AC720%E5%8F%B7%E3%80%81%E5%B9%B3%E6%88%9018%E5%B9%B4_(%E3%83%8D)_%E7%AC%AC1010%E5%8F%B7
- 福岡市「教師によるいじめ」事件 - Wikipedia, 6月 28, 2025にアクセス、 https://ja.wikipedia.org/wiki/%E7%A6%8F%E5%B2%A1%E5%B8%82%E3%80%8C%E6%95%99%E5%B8%AB%E3%81%AB%E3%82%88%E3%82%8B%E3%81%84%E3%81%98%E3%82%81%E3%80%8D%E4%BA%8B%E4%BB%B6
- 児童虐待に関する文献研究 - 子どもの虹情報研修センター, 6月 28, 2025にアクセス、 https://www.crc-japan.net/wp-content/uploads/2021/12/%E5%85%90%E7%AB%A5%E8%99%90%E5%BE%85%E3%81%AB%E9%96%A2%E3%81%99%E3%82%8B%E6%96%87%E7%8C%AE%E7%A0%94%E7%A9%B6%E3%80%80%E5%85%90%E7%AB%A5%E8%99%90%E5%BE%85%E9%87%8D%E5%A4%A7%E4%BA%8B%E4%BE%8B%E3%81%AE%E5%88%86%E6%9E%90%EF%BC%88%E7%AC%AC2%E5%A0%B1%EF%BC%89.pdf
- でっちあげ 殺人教師と呼ばれた男 : 作品情報・キャスト・あらすじ - 映画.com, 6月 28, 2025にアクセス、 https://eiga.com/movie/103667/
- でっちあげ|福田ますみ|福岡殺人教師事件の真相|感想 | チェルミーの読書日記, 6月 28, 2025にアクセス、 https://ameblo.jp/mylibrary1/entry-12904037238.html
- 【楽天市場】でっちあげ 福岡「殺人教師」事件の真相 (新潮文庫 新潮文庫) [ 福田 ますみ ](楽天ブックス) | みんなのレビュー·口コミ, 6月 28, 2025にアクセス、 https://review.rakuten.co.jp/review/item/1/213310_13459272/1.1/
- 【感想・ネタバレ】でっちあげ―福岡「殺人教師」事件の真相―のレビュー - ブックライブ, 6月 28, 2025にアクセス、 https://booklive.jp/review/list/title_id/406987/vol_no/001
- 【ネタバレ】でっちあげ―福岡「殺人教師」事件の真相―の感想・評価 / ネタバレレビュー一覧 - ビジネス・実用 - 無料で試し読み! - DMMブックス, 6月 28, 2025にアクセス、 https://book.dmm.com/product/726494/k077ascsh01965/spoiler/
- 重版出来!『でっちあげ―福岡「殺人教師」事件の真相』決定版! - HONZ, 6月 28, 2025にアクセス、 https://honz.jp/articles/-/42678
足底筋膜炎でも踵部脂肪体症候群でもなく足根管症候群なのか?
ふと思ったのだが、 水泳していると足が痛くなり、さらにお風呂に入るときも痛くなる。
PTの先生曰く、プールは問題ないとのことだけど、それは一般的なリハビリにおいて負担が少ないからという意味だと思う。
毎回お決まりのように痛くなるので、調べてみたら 足根管症候群なのかもしれない。
三好ヶ丘整形外科ブログより、以下引用
足根管症候群とは 足根管は内側くるぶしの後ろ下にあり、管状になっています。管状の中に後脛骨筋腱長拇指屈筋腱、長趾屈筋腱、後脛骨動静脈、脛骨神経があるのですが、脛骨神経が圧迫されて痛みが生じます。
足関節の内側くるぶしの後ろ下から踵の底に鈍痛が生じます。時には針で刺すような痛みや違和感などを感じること があります。荷重時に症状が悪化しますが、寝ているときやお風呂入っている時ににも痛みが強くなることもあります。
とにかく自分の病気を特定して欲しい。福岡にそんな病院がないのだろうか。
踵部脂肪体症候群の悪循環
踵の痛みが治らない、そして足の裏がすぐ疲れる。この2点はそれぞれが以下のような悪循環を元に生じているのではないかと感じた。
- 踵が痛いからそれをかばって前体重になる。
- 前体重になることでアキレス腱やふくらはぎ辺りに力が入り、さらに足にも負担がかかる
- 結果的に足がすぐ疲れ、アキレス腱周辺の筋肉が硬直し足底筋膜炎につながる
この悪循環で踵部脂肪体症候群ほか足底筋膜炎にもつながり治りにくくなっているんじゃないかと。
実際に前重心なのはリハビリの先生に指摘されたし、鏡を見てもそうだった。
理想的にはくるぶしのやや前のほうに重心が来るようにすること。 ただ、実際にそこに重心があるというのはなかなか分かりづらい。 鏡を常に見るわけにも行かないし、足裏にセンサーがあって、重心がズレたら教えてくれるようなデバイスがあればいいんだが。
これはやるとして、あとはバランスボードに乗ってコンディショニングすることも良さそう。
 バランスボード ミッドナイトグリーン ウォブル プラスチック 【日本正規輸入品】 PGJH")

ただし、結局重心が治ったところで、踵への負担は前重心よりも増えるわけで、 踵の痛みを低減する必要があり、ここでテーピングの必要性があるということ。
よって、
- 重心を整える
- テーピングを行う
をセットで行う必要があるのかなと思う。
 伸縮 テーピングテープ 肩 膝 足首 手首 ふくらはぎ 足裏 指 キネシオテープ テーピングテープ")
踵部脂肪体症候群の悪循環
- 踵が痛いからそれをかばって前体重になる。
- 前体重になることでアキレス腱やふくらはぎ辺りに力が入り、さらに足にも負担がかかる
- 結果的に足がすぐ疲れ、アキレス腱周辺の筋肉が硬直し足底筋膜炎につながる
こんな感じだと思う。この悪循環で踵部脂肪体症候群ほか足底筋膜炎にもつながり治りにくくなっているんじゃないかと。
実際に前重心なのはリハビリの先生に指摘されたし、鏡を見てもそうだった。
理想的にはくるぶしのやや前のほうに重心が来るようにすること。 ただ、実際にそこに重心があるというのはなかなか分かりづらい。 鏡を常に見るわけにも行かないし、足裏にセンサーがあって、重心がズレたら教えてくれるようなデバイスがあればいいんだが。
これはやるとして、あとはバランスボードに乗ってコンディショニングすることも良さそう。
ただし、結局重心が治ったところで、踵への負担は前重心よりも増えるわけで、 踵の痛みを低減する必要があり、ここでテーピングの必要性があるということ。
よって、
- 重心を整える
- テーピングを行う
をセットで行う必要があるのかなと思う。
足底筋膜炎と踵部脂肪体症候群の違い
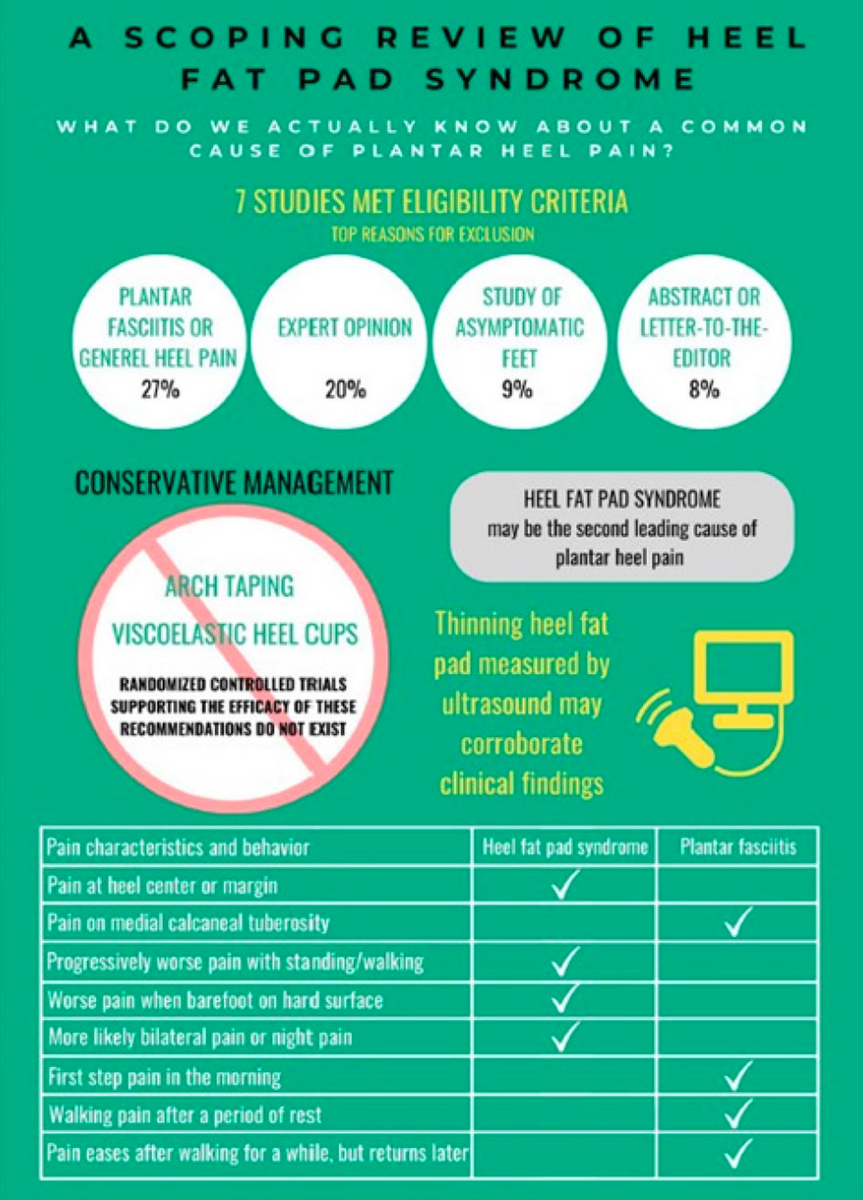
足底筋膜炎(Plantar Fasciitis)と踵部脂肪体症候群(Heel Fat Pad Syndrome; HFPS)の症状の違いを調べてみた。
自分の病気はどちらか確かめたいからだ。 結果は以下。
| 痛みの特徴 | 踵部脂肪体症候群 | 足底筋膜炎 | 自分の症状 |
|---|---|---|---|
| 踵の中心や縁に痛みがある | ○ | ✅ | |
| 踵骨内側結節の痛み | ○ | ||
| 立っているとき、歩いているときの痛みがだんだんひどくなる | ○ | ✅ | |
| 裸足で硬いところを踏むと痛む | ○ | ✅ | |
| 両側性疼痛や夜間痛が起こりやすい | ○ | ✅ | |
| 朝の最初の一歩が痛い | ○ | ||
| 休み明け歩行が痛い | ○ | ||
| 歩けば痛みは和らぐが、またすぐ戻る | ○ | ✅(以前はそうだった) |
つまり自分の場合は、(あくまでも自己判断だけど)踵部脂肪体症候群の疑いが強いという判断になる。
医者に渡した問診票では過去に通院した病院の診断結果より「足底筋膜炎」と記載したが、もしかするとミスリードになっていたのかもしれない。 本当はどちらかまたはそれ以外の症状である可能性もあって、自分からその可能性を否定するような記載をしてはいけなかったなと反省。
正直なところ、踵部脂肪体症候群というのがどこまでメジャーな病気なのかわからない。 少なくとも足底筋膜炎のほうが遥かにメジャーだということは、通院経験からわかる。 足の裏が痛い場合、ほとんどが足底筋膜炎なんだろうなと。
だから、より足の裏に詳しい医者に出会いたい気持ちはあるが、そのためにドクターショッピングを繰り返すのは正直疲れるし、 見つかったとしても自宅から遠いと通う気になれない。それでも例えば1ヶ月で完治する、または確実に良くなる自宅でできるコンディショニング方法を教えてくれるなら通いたいが。
参考
上記サイトより抜粋
足底筋膜炎治療日記 リハビリと診察
今日はリハビリに行ったが、間が空いてるからと診察も受けた。
リハビリは今日はかかと部への体外衝撃派。拡散式なのでそこまで効果はないのかもしれない。 あとは個人的には足底筋膜炎よりも踵部脂肪体症候群を疑っているので、かえって逆効果なのかなという不安もある。 いつも体外衝撃波後はかかと部がジンジンする。いつも夜にジンジンしだすが、体外衝撃波のあとはすぐにジンジンする気がする。
その後は診察だが、とりあえずかかとに衝撃を与えないようにとアドバイスを貰った。 特に筋トレは週5で行っているが、スクワットやデッドリフトなど、足底部への衝撃が伴う種目は禁忌とのこと。 こないだ熱が出て1週間ほど筋トレができなかったがそれでも良くならなかったことを伝えると、 1週間程度じゃ足りないみたいで、とりあえず1ヶ月位は種目を選ぼうと思う。 でもなんとなくだけど良くならない気がするんだよなあ、、、
足底筋膜炎 セルフ問診票
通院する際に、初診で問診票を書くと思うが、そこに手書きで書くのが面倒であり、その場で書くと詳細に書けないため前もって用意している。 過去に数か所持って行っているが、どの先生も快く受け取ってくれるし、褒められたりもするので双方にとってメリットがあるのかなと。皆さんも是非。
痛みの場所
- 両足裏の真ん中あたりと踵

- 両足裏の真ん中あたりと踵
痛みの始まり
- 2022年10月初旬ごろから右足裏の真ん中らへんに違和感
- 歩いていると、足の裏にシールが貼りついている感覚だった。
- 違和感が徐々に痛みになっていき、自転車を漕ぐ時に痛みがあった
- 2023年2月末ごろから右足の踵が徐々に痛くなる
- 2023年3月初旬ごろから左足裏の真ん中らへんに違和感がでてきて、同時に踵が徐々に痛くなる
痛みの程度
- 立っていると数秒で痛くなる(ピリピリする痛み)
- 自転車を漕ぐと、足裏の真ん中らへんが痛い(鋭痛)
- 寝ていても、踵(アキレス腱付近)が布団に触れると少し痛い(鈍痛)
- 座っているときも、我慢できるが足裏と踵に鈍痛がある
痛みのタイミング
- 立って静止しているとき、自転車を漕いでいるときに痛む
- 歩いていると痛みが減る
痛みの持続時間
- 立っている間はずっと痛い、徐々に痛みが増していく
- 自転車を漕いでいる間も痛いが、痛みは増してこない
既往歴・家族歴:
- 足の怪我については特になし
- 慢性前立腺炎発症中
試した対策
- T整形外科と、I医院に通ったが、改善せず
- I医院では、「体外衝撃波」について相談したが、ここには置いてないので他の病院を探すといいかもとアドバイスをもらった
- 併設の通所リハでついでに足もみてもらってストレッチやコンディショニングをしてもらったが改善せず。
- T整形外科では、プレガバリンを処方してもらったが改善せず。
- I整形外科では、以下を処方と、かかとに注射をしてもらって少しだけ改善した。
- 治打撲一方
- 疎経活血湯
- 薏苡仁湯
- ケトプロフェンテープ
- T整形外科と、I医院に通ったが、改善せず
思い当たる原因
- 1年ほど前から慢性前立腺炎になって以来スタンディングデスクで仕事をしているため1日立ちっぱなしだったことが原因かもしれない
- ちょっと硬めのサンダルを履いていた
- 週5で筋トレしているためそれが少しは原因になっているかもしれない
- 1年ほど前から慢性前立腺炎になって以来スタンディングデスクで仕事をしているため1日立ちっぱなしだったことが原因かもしれない